Have you ever thought about deploying a fancy project like a search engine to a server made accessible to everyone just like Larry Page and Sergey Brin did 20 years ago? Follow the steps! Your dreams are at reach.
Before Start
How amazing! This is homework for one of my university courses – Advanced Data Structure and Algorithms Analysis. I share this to all of you just to show how simple a search engine can be. It simply crawls about 1000 pages of the full work of the famous playwriter Shakespeare at shakespeare.mit.edu, indexing it, and serving the search engine to the public.
This is a tutorial based on the Linux Operating System(Ubuntu 18.10), most of the other versions should be supported as well, but the commands may vary a little bit. I have also tested the project on max OS X, the indexing time was about 1.5 hours, a little bit too long and the machine kept sweating. So I think it should be a good choice to run the program on the server directly. I finished in 2 weeks(actually mostly the whole night before the DDL) and I think you can deploy it in an hour (half of the time deployed automatically).
Clone the Whole Project & Overview
I have made this project open-source, so you can download it directly from my GitHub using the following command.
$ git clone https://github.com/Bill0412/shakespeare-search-engine.git
To have an overview of the whole project, you can use the following commands:
$ cd shakespeare-search-engine
or using a simpler one,
$ cd shake*
where * matches all the words you omit for convenience. Cool, right?

Using (which means list all the files in the directory)
$ ls
You can now see all the files for the project as the following:

Since I did not upload the index files to GitHub, you have to generate the folders for data storage yourself:
$ mkdir data $ mkdir data/nodes
Now, after an overview, we are ready to install the dependencies.
Get Dependencies Installed
Next, we will have the environment set up. As you can see, if we run the program directly, we tend to get errors, since more some dependencies are not on the server.

Setting up the Environment
I have estimated for you that there are 3 packages needed for this project, 2 for crawling, indexing the pages and 1 for the webserver.
Install python3-bs4
We use BeautitulSoup to parse the HTML file, get the links inside a page, etc.
$ apt-get install python3-bs4
enter y, then the process will be finished in no time. (In this tutorial, if it is not specified, always enter y)
Install nltk
nltk is a package that makes NLP(Natural Language Processing) Really easy.
When you try to install pip3 install nltk, you may encounter:

Follow the instructions:
$ apt install python3-pip
What the hell! Is the system joking me? E: Unable to locate package python3-pip???

Don’t worry, the following lines will help
$ echo " deb http://archive.ubuntu.com/ubuntu bionic main universe deb http://archive.ubuntu.com/ubuntu bionic-security main universe deb http://archive.ubuntu.com/ubuntu bionic-updates main universe " >> /etc/apt/sources.list $ sudo apt update $ sudo apt install python3-pip
Now feel free to install nltk!
$ pip3 install nltk
Install flask
Flask is a light-weight web framework that uses python.
$ pip3 install flask
Last Check
Before moving on, you should make sure that the previous steps are set up correctly.
$ python3 >>> import bs4, nltk, flask >>> exit()
If no error occurs, you are free to move on!
Crawling & Indexing
This step will take roughly half an hour on a server with 1 Core CPU 1GB RAM. Make sure you are at the shakespeare-search-engine directory:
$ nohup python3 shakeCrawler.py &

Now a background task is grabbing and analyzing every single word of the webpage shakespeare.mit.edu for you, which makes the search engine faster later. All the pains and waiting will payback!
Run the webserver
Now it’s the last step to go!
About half an hour later log back into your server. To check if the indexing was successful:
$ cd shake* $ ls data
If you see exactly the same files as following, you are safe to go.

This is the last step, I promise!
$ nohup python3 app.py &
Now your search engine is running, to try it, just enter the IP address of your server in your browser.
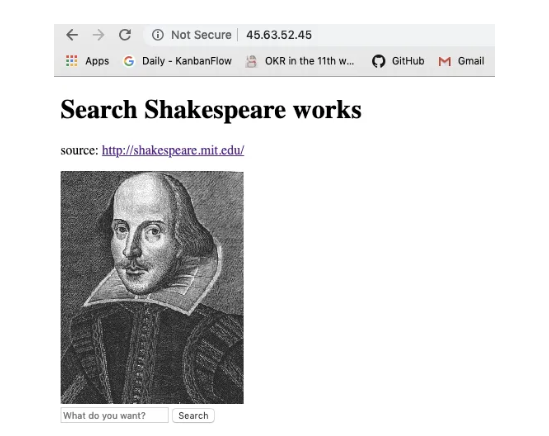
I searched lear, following is the result:

Bonus: Download the index to Local for Fun
As I have said, generating the index at a local machine is not that fun – hours will be taken. So, to make it easy, you can download the index to your local machine, run it, edit the code have more fun.
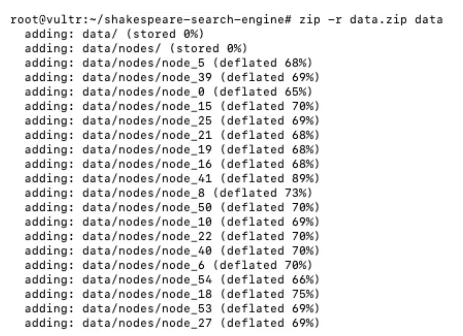
On the server:
$ sudo apt-get install zip $ zip -r data.zip data
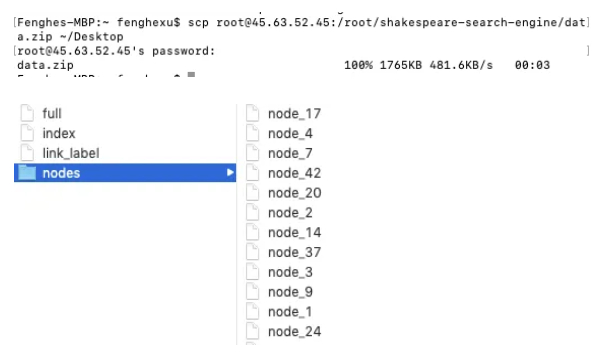
On your local machine: (157.230.131.192 should be replaced by your server address)
$ scp [email protected]:/root/shakespeare-search-engine/data.zip ~/Desktop
This command is run on macOS, the data.zip file should be at the desktop after running this command.
References
- Beautiful Soup Docs: https://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup
- Install pip3: https://askubuntu.com/questions/1061486/unable-to-locate-package-python-pip-when-trying-to-install-from-fresh-18-04-in#answer-1061488
- Shell append multiple lines to a file: https://unix.stackexchange.com/questions/77277/how-to-append-multiple-lines-to-a-file
- Create zip file: https://www.wpoven.com/tutorials/server/how-to-zip-or-unzip-files-and-folders-using-command-line-on-ubuntu-server
- Download using scp: https://stackoverflow.com/questions/9427553/how-to-download-a-file-from-server-using-ssh